




 exam: Ultimate Guide")









Anyone who raised the sites knows that it is worthwhile to start the web server, as requests begin to come to it. Also, DNS does not really know about it, and in the httpd error log file there are already full records like this:
It became interesting to me, and I decided to study this issue deeper. As soon as time appeared, I wrote the web server log parser. Since I love clarity, I placed the results on the map.
And here’s the picture:
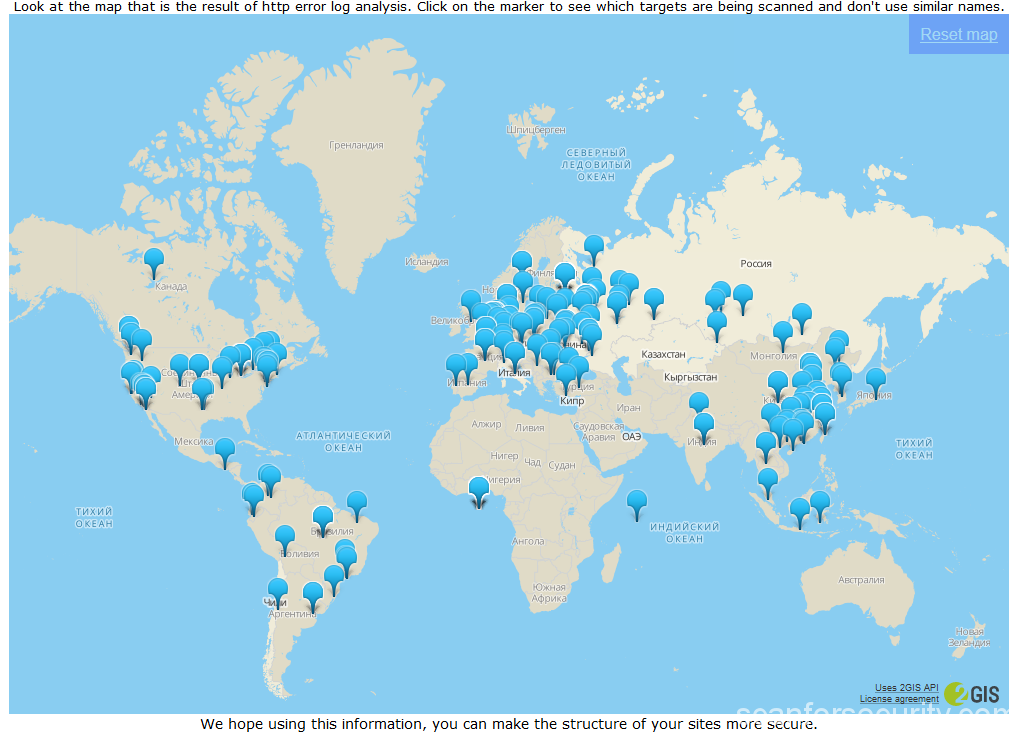
On the map markers indicate the locations determined by the IP addresses of the scan sources. To obtain information, a free offline library SxGeo was used, and for display – 2GIS API. Of course, because of free of charge, the SxGeo library does not have high accuracy, and some addresses fall into the ocean. However, over time (at the moment I have accumulated statistics for 2 months), the picture becomes quite clear outlines.
Surely some of the addresses are proxy. At the same time, the sources of scanning almost uniformly cover the most developed in the sense of IT regions of the world.
However, as our beloved Mikhail Sergeyevich Boyarsky would say – “A thousand devils,” what’s wrong with Australia?
In addition to distributing the scan sources, it was also interesting for me to collect the target paths that scanners check. Such was quite a lot. Below I will give only a small part of the targets for an example:
var/www/html/RPC2 /var/www/html/SQLite /var/www/html/SQLiteManager /var/www/html/SQLiteManager-1.2.4 /var/www/html/SQlite /var/www/html/Snom /var/www/html/Version.html /var/www/html/Yealink /var/www/html/\xd1\x86\xd1\x80\xd1\x89\xd1\x8b\xd1\x81\xd1\x84\xd1\x82\xd1\x8c\xd1\x83 /var/www/html/_PHPMYADMIN /var/www/html/_pHpMyAdMiN /var/www/html/_phpMyAdmin /var/www/html/_phpmyadmin /var/www/html/_query.php /var/www/html/_whatsnew.html /var/www/html/adm /var/www/html/admin /var/www/html/admin.php /var/www/html/admin888 /var/www/html/admin_area /var/www/html/admin_manage / var / www / html / admin_manage_access / var / www / html / admindb / var / www / html / administrator /var/www/html/administrator.php / var / www / html / adminzone Often there is a game with a register: /var/www/html/_PHPMYADMIN /var/www/html/_pHpMyAdMiN /var/www/html/_phpMyAdmin /var/www/html/_phpmyadmin There are also exotic targets, which certainly have nowhere to take from me: /var/www/html/w00tw00t.at.blackhats.romanian.anti-sec /var/www/html/nmaplowercheck1523152976 /var/www/html/elastix_warning_authentication.php
A full list of the taggts you can pick up from the link in the basement. The catching system now operates in an automatic mode and means it is constantly replenished.
Well, but what to do about it? The information received by us, like any other, can be used in different ways.
For example:
When creating sites, especially based on standard CMS and using standard DBMS, it is desirable to change the standard names of directories and files. Do not leave the installation directories after the installation is complete. Do not put configuration files in the root directory or folder named “configuration”, “config”, etc.
It can be blocked at the iptables level of the addresses from which the scan is conducted. Of course this is an extreme case, but there is such an opportunity and it can be automated.
Using the dictionary of captured target, you can check the structure of the site for matches. for this, the simplest script is used.
And another way to use “cool hackers” for their own purposes is to increase the attendance of the site. This is a joke and no.
This really works if you create files on your site on the basis of the tagged tagger dictionary, and place arbitrary text and the counter code inside. This works of course only if the scanner can perform JS (an addition from apapacy ).
And this is a joke, because really unique IP addresses of scanners are not so much. At me for 2 months they were caught 275. How many among them “clever” bots and browsers did not consider. Maybe not at all.
It should be noted that from some addresses, scanning was observed once, while from others it was performed daily. But this process is permanent. I wonder what proportion of traffic on the web is scanned traffic. Apparently not a very big time no one is fighting this.
Question: Do you need to pay attention to scanning and what should you do to avoid getting scanners?
PS
The phenomenon of scanning, although man-made, but it seems already has become a natural process for the Internet. It was there and as long as the Network exists. This is a harmful factor, from which you can protect yourself as glasses from the solar ultraviolet.
I will summarize some of the results of the discussion:
1. Australia does exist but the Internet is expensive there and it is not enough. The same with the NZ. But there is an ocean, beaches and kangaroos.
2. Scanning web resources is a special case of scanning real Internet addresses in general. Targets are almost all standard ports and standard software, and the geography of scan sources coincides with the geography of having “fast” Internet access.
3. Scanners do not just work. Scanning is the first stage of hacking. Scanners search for possible vulnerabilities. The presence of such vulnerabilities can be used to infect the servers with malicious software and / or to gain access to personal information.
4. The comments discuss ways to protect elementary scanners. The basic directions: change of standard settings of software, detection and blocking of scanners by banlist.
All of the above is obvious. But the knowledge and understanding of such things accurately helps to create conditions for the safe operation of your resource.








{kind=link}